
Is Google using a ChatGPT-like system for spam and AI content detection and ranking websites?
The headline is intentionally misleading – but only insofar as using the term “ChatGPT” is concerned.
“ChatGPT-like” immediately lets you, the reader, know the type of technology I’m referring to, instead of describing the system as “a text-generation model like GPT-2 or GPT-3.” (Also, the latter really wouldn’t be as clickable…)
What we will be looking at in this article is an older, but highly relevant Google paper from 2020, “Generative Models are Unsupervised Predictors of Page Quality: A Colossal-Scale Study.”
What is the paper about?
Let’s start with the description of the authors. They introduce the topic thusly:
“Many have raised concerns about the potential dangers of neural text generators in the wild, owing largely to their ability to produce human-looking text at scale.
Classifiers trained to discriminate between human and machine-generated text have recently been employed to monitor the presence of machine-generated text on the web [29]. Little work, however, has been done in applying these classifiers for other uses, despite their attractive property of requiring no labels – only a corpus of human text and a generative model. In this work, we show through rigorous human evaluation that off-the-shelf human vs. machine discriminators serve as powerful classifiers of page quality. That is, texts that appear machine-generated tend to be incoherent or unintelligible. To understand the presence of low page quality in the wild, we apply the classifiers to a sample of half a billion English webpages.”
What they’re essentially saying is that they have found that the same classifiers developed to detect AI-based copy, using the same models to generate it, can be successfully used to detect low-quality content.
Of course, this leaves us with an important question:
Is this causation (i.e., is the system picking it up because it’s genuinely good at it) or correlation (i.e., is a lot of current spam created in a way that is easy to get around with better tools)?
Before we explore that however, let’s look at some of the authors’ work and their findings.
The setup
For reference, they used the following in their experiment:
- Two text-generation models, OpenAI’s RoBERTa-based GPT-2 detector (a detector that uses the RoBERTa model with GPT-2 output and predicts whether it is likely AI-generated or not) and the GLTR model, which also has access to top GPT-2 output and operates similarly.
We can see an example of the output of this model on the content I copied from the paper above:
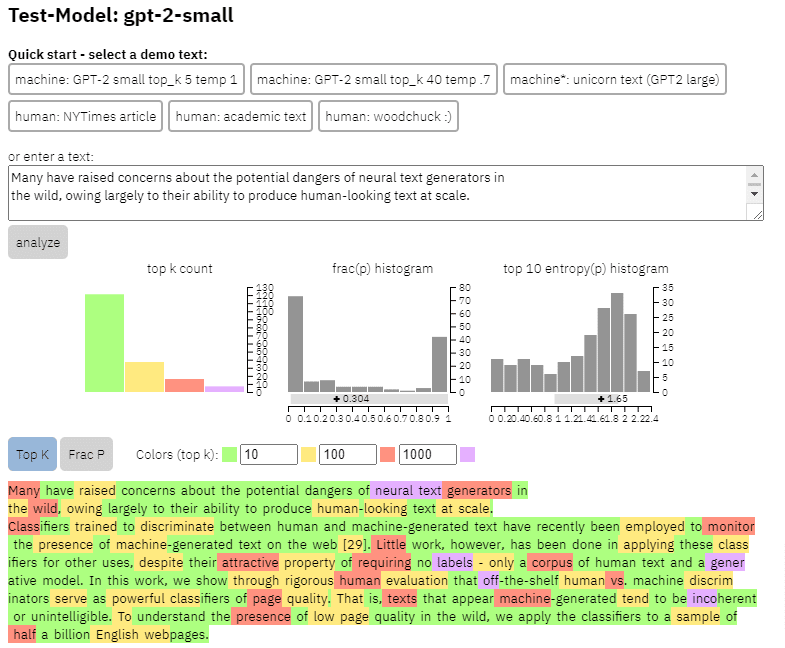
- Three datasets Web500M (a random sampling of 500 million English webpages), GPT-2 Output (250k GPT-2 text generations) and Grover-Output (they internally generated 1.2M articles using the pre-trained Grover-Base model, which was designed to detect fake news).
- The Spam Baseline, a classifier trained on the Enron Spam Email Dataset. They used this classifier to establish the Language Quality number they would assign, so if the model determined that a document is not spam with a probability of 0.2, the Langage Quality (LQ) score assigned was 0.2.
An aside about spam prevalence
I wanted to take a quick aside to discuss some interesting findings the authors stumbled upon. One is illustrated in the following figure (Figure 3 from the paper):

It's important to notice the score below each graph. A number toward 1.0 is moving to a confidence that the content is spam. What we're seeing then is that from 2017 onward – and spiking in 2019 – there was a prevalence of low-quality documents.
Additionally, they found the impact of low-quality content was higher in some sectors than others (remembering that a higher score reflects a higher probability of spam).

I scratched my head on a couple of these. Adult made sense, obviously.
But books and literature were a bit of a surprise. And so was health – until the authors brought up Viagra and other "adult health product" sites as “health" and essay farms as "literature" – that is.
Their findings
Aside from what we discussed about sectors and the spike in 2019, the authors also found a number of interesting things that SEOs can learn from and must keep in mind, especially as we start to lean on tools like ChatGPT.
- Low-quality content tends to be lower in length (peaking at 3,000 characters).
- Detection systems trained to determine whether text was written by a machine or not are also good at classifying low vs. high-level content.
- They call our content designed for rankings as a specific culprit, though I suspect they're referring to the trash we all know shouldn't be there.
The authors do not claim that this is an end-all-be-all solution, but rather a starting point and I'm sure they've moved the bar forward in the past couple of years.
A note about AI-generated content
Language models have likewise developed over the years. While GPT-3 existed when this paper was written, the detectors they were using were based on GPT-2 which is a significantly inferior model.
GPT-4 is likely just around the corner and Google's Sparrow is set for release later this year. This means that not only is the tech getting better on both sides of the battleground (content generators vs. search engines), combinations will be easier to pull into play.
Can Google detect content created by either Sparrow or GPT-4? Maybe.
But how about if it was generated with Sparrow and then sent to GPT-4 with a rewrite prompt?
Another factor that needs to be remembered is that the techniques used in this paper are based on auto-regressive models. Simply put, they predict a score for a word based on what they would predict that word to be given those that preceded it.
As models develop a higher degree of sophistication and start creating full ideas at a time rather than a word followed by another, the AI detection may slip.
On the other hand, the detection of simply crap content should escalate – which may mean that the only "low quality" content that will win, is AI-generated.
The post Is Google using a ChatGPT-like system for spam and AI content detection and ranking websites? appeared first on Search Engine Land.
from Search Engine Land https://searchengineland.com/google-study-generative-models-redictors-page-quality-392460
via free Seo Tools